Two-Model Approach로 구현하는 온라인 디지털 트윈의 진화: 미러링에서 자율운전까지
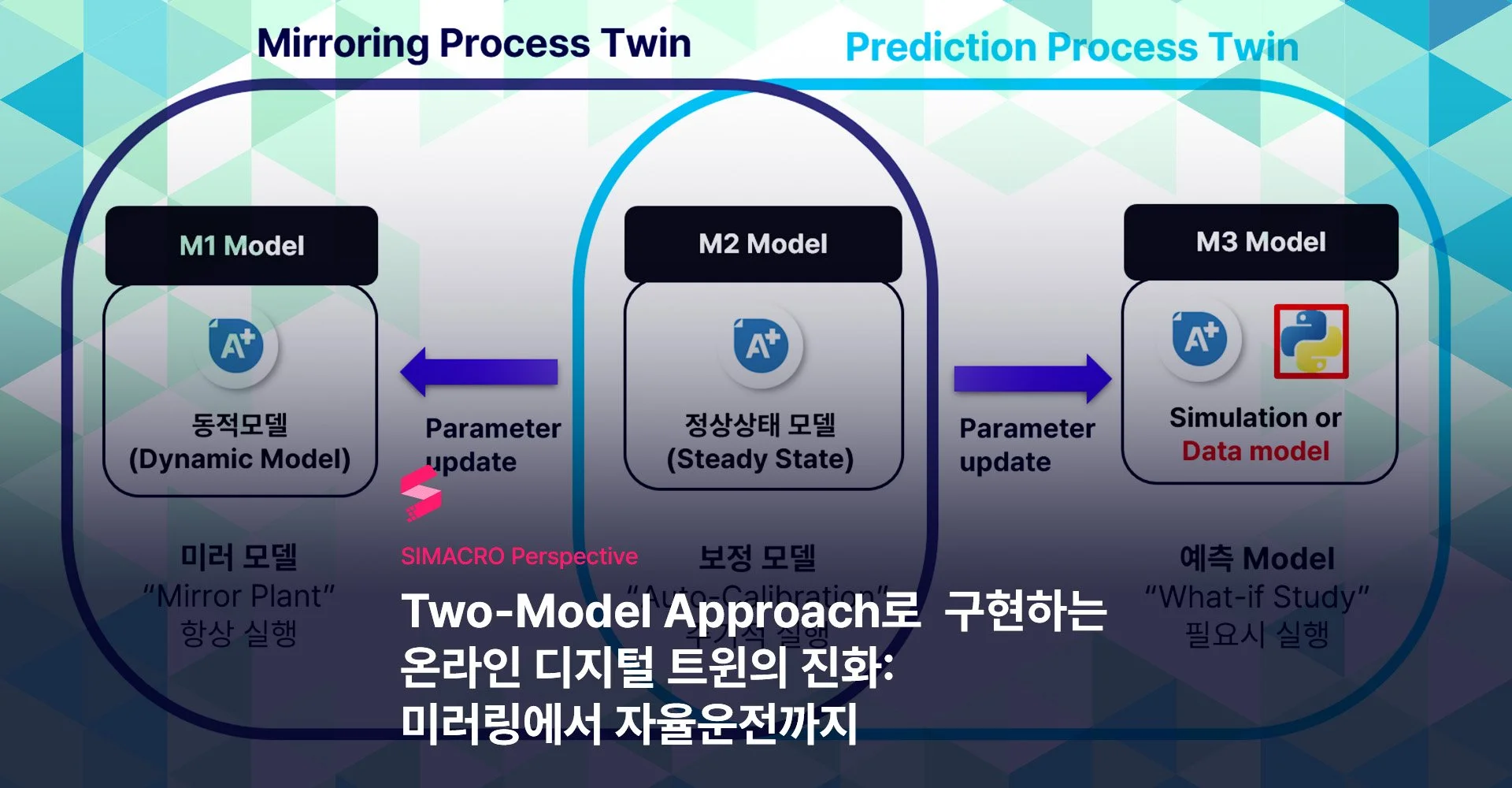
공정 디지털 트윈을 위한 M1+M2+M3 아키텍처의 이해
공정 산업의 온라인 디지털 트윈 개념과 구현 방식은 근본적인 변화를 겪고 있습니다. 많은 사람들이 여전히 온라인 디지털 트윈을 단순히 실시간 데이터와 시뮬레이션 모델의 연결, 그리고 계산 결과의 시각화 정도로 인식하고 있지만, 실제로는 훨씬 더 정교한 개념과 방법론이 필요합니다. 진정한 온라인 공정 디지털 트윈은 장치의 성능 저하를 지속적으로 반영하고, 경제성을 위한 새로운 생산 전략을 수립하였을 때, 다양한 운전 상황을 신속하게 반영할 수 있는 구조여야 합니다시마크로의 이원석 본부장 님이 Two-Model Approach (M1+M2)에 대한 인사이트를 링크드인에 공유한 후, 공정 산업 전문가들로부터 큰 관심을 받았습니다. 해당 글에는 온라인 공정 디지털 트윈의 1단계로서 미러링 디지털 트윈의 역할과 목적을 설명하고, 이를 구현하기 위한 Two-Model Approach (M1+M2)에 대한 인사이트가 담겨있었습니다. 댓글에서는 구현의 복잡성, 자율운전으로의 진화, 실제 적용 사례 등 다양한 주제에 대한 깊이있는 질문과 토론이 활발히 이어졌습니다.이러한 인사이트들을 더 많은 분들이 쉽게 접할 수 있도록, 이번 글에서 하나의 종합적인 아티클로 정리했습니다.
디지털 트윈의 진화 : 단순한 미러링을 넘어서
많은 사람들은 여전히 미러링을 단순히 실시간 데이터를 모델에 입력하고 시뮬레이션 결과를 얻는 것으로 생각합니다. 그러나 화학 공정과 장치에서는 시간이 지남에 따라 필연적으로 성능 저하가 발생합니다. 오염 계수 증가, 압축기 효율 저하, 촉매 활성도 저하 등과 같은 현상들입니다.따라서 진정한 미러링은 실시간 데이터로부터 시뮬레이션 결과를 얻는 것을 넘어서, 성능 저하를 고려한 주기적인 매개변수 보정을 포함해야 합니다.
시마크로의 Two-Model 접근법
시마크로의 PMv(ProcessMetaverse)는 Two-Model 방법론 기반 미러링 디지털 트윈을 손쉽게 구현합니다.M1 (미러 모델, Mirror Model): 동적 모델로서 플랜트의 운전 상황과 거동을 투영하며, 실시간 운전 데이터가 입력되어 플랜트와 동기화를 유지합니다M2 (보정 모델, Calibration Model): 정상상태 모델로서 주기적으로 실행되며, 플랜트와 미러 모델의 차이를 최소화하기 위해 매개변수(예: 오염 계수, 회전기 효율, 촉매 활성도)를 조정합니다.중요한 점은 M1과 M2의 유기적 관계를 만들고 실용적인 동기화를 위해서는 사용하는 시뮬레이션 Software가 Open-Form Equation을 지원하는 것입니다. 이러한 구조는 M2 모델에서 매개변수 보정을 유연하게 가능하게 하고 M1 모델에 새로운 매개변수가 원활하게 업데이트될 수 있도록 합니다.이러한 접근 방식을 통해 PMv에서는 실시간 운전 데이터 입력으로 시뮬레이션 모델을 실행하는 것 뿐만 아니라, 시간이 지남에 따라 플랜트의 열화 상태를 반영하는 진정한 디지털 트윈 1단계 미러링을 가능하게 합니다.
온라인 공정 디지털 트윈 : 왜 Two-Model 접근법(M1 + M2)인가?
왜 미러링에는 Two-Model 접근법(M1 + M2)이 필요한지 질문하는 분들이 계셨습니다. 핵심 이유는 미러링에서 ‘플랜트의 다양한 동적 상태 및 응답을 재현하는 것’과 ‘장치 설비의 열화 상태를 지속적으로 반영하는 것’이 중요하기 때문입니다.
단일 정상상태 모델의 한계
단일 정상상태 모델로는 다음을 포착할 수 없습니다:
저장 탱크(Inventory Tanks)의 액상 레벨과 물질 수지가 동적인 변화
시동, 정지 또는 원료 교체와 같은 전환 단계(Transition phases)
리사이클과 피드백 제어루프(Recycle and feedback loops)에 의한 유량과 압력의 불안정한 상황
제어기의 구성과 동작(Control actions)에 의한 플랜트의 동적 응답
압력/온도 또는 SOC가 시간에 따라 변화하는 에너지 저장 시스템(ESS, Steam Header )
본질적으로 시간 차원이 필요한 배치 또는 반배치 운전(Batch or semi-batch operations)
해결책: 동적 + 정상상태 통합
그렇기 때문에:
M1 (미러 모델, Mirror Model)은 동적 모델로, 플랜트의 동적 상태를 추적하면서 연속적인 메타 데이터를 생성하기 위해 항상 실행됩니다.
M2 (보정 모델, Calibration Model)은 정상상태 모델로, 매개변수(오염 계수, 효율, 촉매 활성)를 재보정하고 M1 모델의 높은 미러링 정합성과 정확도를 장기적으로 유지하기 위해 주기적으로 실행됩니다.
이 구조는 미러링 디지털 트윈이 ‘M1에 의한 플랜트의 지속적인 실시간 추적’ 그리고, ‘M2에 의한 상태 정렬’을 모두 가능하게 합니다.
예측 기능으로의 확장
Two-Model 접근법의 또 다른 장점은 예측 디지털 트윈으로 자연스럽게 확장될 수 있다는 것입니다. 미러링 루프(M1 + M2)가 확립되면, 여기에 M3 모델을 추가하여 예측 루프를 구성할 수 있습니다.
M3 (예측 모델): "What-if" 연구, 시나리오 분석 및 온디맨드 최적화(on-demand optimization)에 사용됩니다
이때 M2 모델은 예측 루프에서도 동일한 역할을 수행하며, 보정된 파라미터를 M3 모델에 전달하여 현재 장치 상태를 기준으로 한 What-if 분석을 가능하게 합니다.
산업 구현: 핵심 질문과 전문가 인사이트
M1+M2+M3 아키텍처는 공정 산업 전문가들 사이에서 상당한 관심을 불러일으켰습니다. 실무진들이 제기한 중요한 질문들과, 이에 대한 전문가의 인사이트 및 논의를 소개합니다.
구현 복잡성과 확장성
Q: 여러 모델(M1+M2+M3)을 유지하는 것이 실용적 구현에 있어 너무 복잡하고 자원 집약적이지 않을까요?A: 시뮬레이션 모델이 Equation-Oriented 방식의 시뮬레이터(Aspen Dynamics 등)에서 개발될 때, M1과 M2는 본질적으로 서로 다른 모드로 작동하는 동일한 모델입니다. 별도의 여러 모델로 구성하여 구현하는 것이 아니라 단일한 모델을 유연하게 목적에 맞게 사용하는 것이죠.핵심은 여러 계산 모드의 first-principles 모델, 데이터 기반 모델, 플랜트 데이터를 통합하고 시뮬레이션 결과를 효과적으로 관리하는 데 어려움이 있는 기존 도구의 한계를 극복하는 것입니다.디지털 트윈이 생성하는 막대한 메타 데이터에 대한 통합 관리 기능을 갖춘 현대적인 플랫폼은 다중 모델 디지털 트윈을 실현 가능하게 할 뿐만 아니라 생산 현장에서 신속하게 구현되고, 지속 가능하게 만듭니다. 이것이 바로 ProcessMetaverse (PMv)가 산업용 SaaS 플랫폼으로 개발된 이유입니다.PMv의 아키텍처와 기능에 대한 포괄적인 개요는 이 소개 영상에서 확인할 수 있습니다.
자율 플랜트 운전의 미래
Q: 디지털 트윈이 자율운전으로 어떻게 진화하며, 이러한 변화에서 Gen-AI는 어떤 역할을 하나요?A: 공정 산업은 결국 자율운전으로 나아갈 것이며, 이때 Agentic-AI가 핵심 기술이 될 것으로 생각합니다. 온라인 디지털 트윈에서 생성된 메타 데이터는 Gen-AI가 안정적이고 지능적으로 공정을 운전할 수 있도록 하는 핵심적인 컨텍스트가 됩니다.진행 과정은 다음과 같은 자연스러운 절차를 따를 것입니다. [미러링(M1+M2) → 예측(M3) →의사결정 지원 → 자율적 의사결정]. 풍부한 운전 메타 데이터와 함께 설계 데이터, 표준 운전 절차(SOP) 등 각종 유지보수 문서를 통합하는 디지털 트윈 플랫폼은 Gen-AI의 훈련장이자 운전 컨텍스트 역할을 하며, 지속적인 학습-분석- 적용-수정- 사이클을 구축할 것입니다.
다중 이해관계자 가치 창출
Q: 디지털 트윈이 단일 플랫폼에서 운전자, 엔지니어, 관리자의 서로 다른 요구사항을 어떻게 충족할 수 있나요?A: 실질적인 가치를 창출하려면 디지털 트윈은 각 역할의 특정 KPI에 맞춘 인사이트를 제공해야 합니다. 최근 산업 설문조사는 지속적으로 인터페이스와 인사이트를 적응시키는 통합 플랫폼인 "하나의 솔루션, 여러 관점(One Solution, Multiple Perspectives)"에 대한 니즈를 보여줍니다.
운전자: 실시간 운전 데이터와 알림
엔지니어: 기술 분석 도구와 공정 최적화 인사이트
관리진: 전략적 KPI 대시보드와 성과 지표
이 플랫폼은 단일 데이터 소스를 유지하면서 각 이해관계자의 요구사항에 맞는 차별화된 사용자 경험을 제공합니다.
기술적 구현과 표준
Q: 동적 미러링 구현을 위한 기술적 요구사항은 무엇이며, 산업 표준은 얼마나 중요한가요?A: 미러링 디지털 트윈의 주요 목적은 센싱 데이터를 시드(SEED)로 사용하여 이를 수천 배로 증폭시켜 풍부한 메타 데이터로 만드는 것입니다. M1(First-Principles 동적 모델)은 지속적으로 실행되며, 일반적으로 매분마다 플랜트 운전을 모방하고 광범위한 소프트 센싱 데이터를 생성합니다.First-Principles 기반 M1모델은 순수 데이터 기반 모델과 데이터 증폭 관점에서 근본적으로 구분됩니다. 순수 데이터 기반 모델은 M3 예측 모델에서 First Principles 모델 보다 경우에 따라 효과적일 수 있습니다.표준과 관련해서는 상호 운용성과 유연한 아키텍처가 중요한 요인입니다. 자산 관리 셸(AAS, Asset Administration Shell)은 높은 단계의 디지털 트윈, 즉 응용 전반에 걸쳐 표준화를 가능하게 하는 중요한 역할을 하며, 서로 다른 산업 시스템이 원활히 통합될 수 있도록 합니다.
결론: 지능형 플랜트 운전으로의 길
단순한 미러링에서 자율 디지털 트윈으로의 진화는 공정 산업 디지털화의 근본적인 변화를 나타냅니다. M1+M2+M3 아키텍처는 안정적인 지능형 플랜트 운전의 기반을 제공합니다:
물리적 자산과의 지속적인 동기화 유지 (M1)
매개변수 보정을 통한 장기적 정확성 보장 (M2)
예측 최적화 및 시나리오 분석 활성화 (M3)
공정 산업이 Agentic-AI 기반 자율운전으로 발전해 나가면서, M1+M2+M3 아키텍처가 생성하는 풍부한 메타 데이터는 안정적이고 지능적인 플랜트 운전을 위한 핵심 기반이 될 것입니다.보스턴과 서울에 본사를 둔 시마크로는 지난 2018년부터 40개 기업에서 90개 이상의 상업적 모델링 프로젝트를 완료했습니다. AspenTech, Emerson, OLI 등 글로벌 기술 리더들과 협력하며 공정 산업의 디지털 혁신 발전에 전념하고 있습니다.시마크로 소개이원석 님은 시마크로의 운영 총괄 본부장입니다. 공정 설계, 모델링, 시뮬레이션 분야의 전문가로서 AspenTech에서 공정 산업 분야에서 비즈니스, 솔루션 컨설팅을 20년간 수행하였습니다.이원석 님 소개